Overview
ACCL is a MPI-like library of network communication functions implementing common patterns useful for developing distributed applications. We’ll refer to these patterns by their MPI terminology: collectives. ACCL consists of two parts: the FPGA circuitry required to implement the collectives, and a host driver which configures the FPGA circuits and exposes the functionality they implement to software running on the host. In addition, ACCL includes several software components which ease development of ACCL-enabled applications: A C++ library of functions designed to control the communication from the host and ACCL HLS bindings to control the communication from programmable logic.
CCLO Subsystem
The hardware components of ACCL are together denoted the CCLO Subsystem, which is implemented alongside user kernels in the FPGA accelerator. The CCLO Subsystem enables MPI-like collectives to execute on buffers in FPGA memory or by directly exchanging data with user-defined FPGA kernels. The CCLO subsystem is illustrated in the following diagram. It consists of FPGA kernels, which are callable, i.e. function-like, and IPs, which are continuously running, i.e. thread-like.
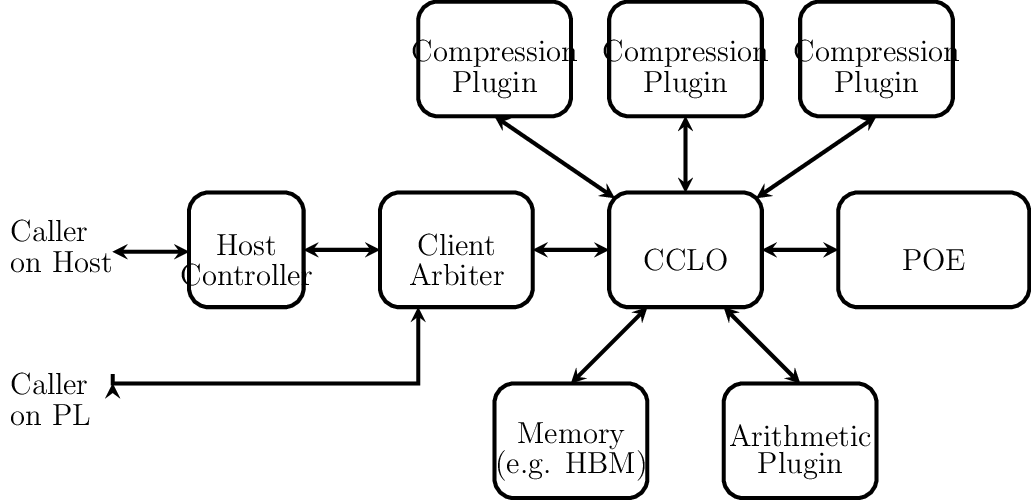
CCLO Subsystem
the Collective Communication Library Offload (CCLO) IP performs data movement and collective orchestration. It is configured once by the host and subsequently operates continuously, executing commands it receives via an argument stream while at the same time managing the network interface.
Protocol Offload Engines (POEs) are IPs which implement communication protocol stacks in hardware, converting between network packets and CCLO messages. The CCLO can talk to several POEs implementing, among others, TCP and UDP.
the Host Controller exposes a function call interface to the CCLO from the host. When the host controller kernel is called by the host program, it passes all its arguments to the CCLO, and waits for a call completion notification from the CCLO before itself returning control to the host program.
the client arbiter IP arbitrates between two kernels commanding the CCLO. Several IPs can be assembled to arbitrate between larger numbers of kernels.
optional arithmetic plugin IPs attach via data streams to the CCLO - two operand streams and one result stream - and perform elementwise arithmetic required in reduction collectives. Users may implement their own arithmetic plugins, with support for arbitrary data types.
optional compression plugin IPs enable the CCLO to cast between datatypes to e.g. compression reduce network data throughput. There are 3 instances of the compression plugin connected to the CCLO, corresponding to the worst-case scenario of a compressed reduction where two operands must be decompressed and the result of the reduction compressed simultaneously.
Users may define their own arithmetic and compression plugins. Compression plugins may also be replaced for other bump-in-the-wire data transformations such as encryption.
ACCL Driver
A typical FPGA-accelerated and ACCL-enabled distributed application software stack is illustrated in the figure below. The application includes an accelerated compute section which calls kernels implemented in the FPGA accelerator. The XRT middleware provides a function-call interface to these hardware-accelerated kernels. The application also requires collective communication for exchanging data with other peers in a distributed system.
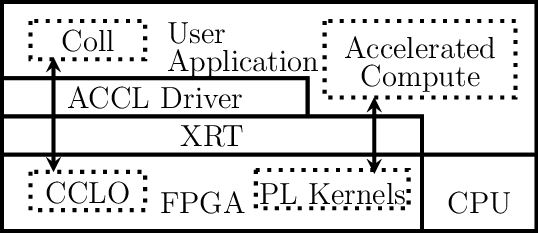
ACCL Software Stack
The ACCL driver configures the CCLO subsystem at application initialization time, and subsequently exposes ACCL functionality to application code running on the system CPUs. The driver transparently utilizes XRT to access registers or call kernels in the CCLO subsystem. The ACCL driver can also switch between real hardware or a software-emulated CCLO subsystem to allow for various levels of application debugging. More details in the page on simulation.
ACCL HLS Bindings
In cases where accelerated compute alternates with communication, and there is a data dependency between the two, the user application may choose to avoid the latency of commanding the two functions via XRT, and instead delegate the task of initiating collective calls to the FPGA-accelerated kernels themselves.
Initiating a collective in the CCLO requires passing a set of function arguments to the CCLO through a stream, i.e. a FIFO-like interface. While writing from a kernel to a stream is readily implemented from C++ by any high-level synthesis (HLS) framework like Vitis, the encoding and meaning of the CCLO arguments is non-obvious. To facilitate kernel development for this application scenario, ACCL provides a small HLS-compatible C++ library which hides most of this complexity and exposes a cleaner interface similar to that of the ACCL host driver.